


Watermarking Generative AI: Ensuring Ownership and Transparency
An overview of existing methods, the visual way

Generative AI spans across diverse modalities including images, text, audio, and video, offering immense potential for innovation and creativity. However, it also has the power to dramatically increase adversarial risks such as biases, hallucinations, the creation of harmful content, privacy violations, fraudulent activities, and the proliferation of misinformation because this technology has more attack surface than any other tool and operates at a scale never seen before.
Should we continue to place trust in the data we encounter online?
Governmental initiatives are underway to address these issues:
The American executive order on AI regulation mandates providers to implement labeling for AI-generated content.
In Europe, the AI Act mandates compliance for General Purpose AI (GPAI) by May 2025.
In order to have more transparency online, a solution emerges: watermarking.
Introduction To Watermarking
Watermarking involves subtly altering data so that it remains identifiable even after data augmentations such as cropping, rotating, filtering, or screenshots.
AI-generated content detection methods generally fall into two groups:
🔴 Passive Methods
These methods analyze unaltered data to identify AI-generated content (e.g., using human inspection or classifiers). However, they're becoming increasingly difficult to execute effectively as AI models tend to generate more and more realistic data.
🟢 Active Methods
These methods actively modify data, like through watermarking or by altering the generation process, to identify AI-generated content.
Overall, passive detection methods are proving less effective over time, while active methods like watermarking are gaining prominence for their robustness. To understand watermarking better, let's explore one application: image watermarking.
Three Key Criteria
When evaluating watermarking models, we consider these three important criteria:
Imperceptibility: The watermark should introduce minimal distortion, remaining invisible to the human eye.
Capacity: The watermark must be able to store sufficient information, such as the date, device type or issuer.
Robustness: The watermark should remain detectable regardless of the transformations applied to the image.
Let's explore how different modalities (image, sound, text) use watermark in their own way to ensure these criteria.
Image Watermarking
Image watermarking involves embedding a subtle, invisible watermark into an image. This watermark is encoded based on a text message.

After the image is published online and subjected to various augmentations, an extraction method can recover the text message, confirming the image's origin.
One type of image watermarks that meet all three criteria belong to a family of watermarking called “Deep Watermarking”, let’s see what it involves.
Deep Watermarking
Deep learning models can be applied to image watermarking through a three-stage process involving an encoder-decoder architecture:

Encoder
The encoder model processes two inputs: a raw image and a text message. Its goal is to create an image that closely resembles the original but contains the embedded text message. The encoder model is optimized using a perceptibility loss, which penalizes excessive deviations from the original image, ensuring that the watermark remains imperceptible.
Random Augmentations
The watermarked image then undergoes random augmentations like cropping, rotation, blurring, and noise addition. This step ensures that the following stage—the extractor—can meet the robustness requirement by retrieving the embedded message even after the image has been transformed.
Extractor
The extractor model takes an augmented, watermarked image and retrieves the original text message. It is optimized using a watermark loss, which penalizes the model for failing to reconstruct the hidden message accurately.
Training
This architecture is typically trained end-to-end which means that both networks (the extractor and the encoder) are trained simultaneously.
Next, let's explore how these methods can be applied to image generation.
Image watermarking in practice
Now that we've seen the theory behind image watermarking, let's see how it is implemented in practice in user-facing models.
Diffusion models

Let's quickly review how modern image generation models operate.
Most current models, like Stable Diffusion and DALL-E, are based on diffusion models. The core concept is the following: starting with random noise and a text prompt of the desired image, the model iteratively removes the noise until the final image is created via a decoder.
Watermarking in Stable Diffusion
Since its release in 2022, Stable Diffusion initially used post-hoc watermarking, which embedded a watermark within inference code after the image was generated. However, this method was easy to bypass by simply commenting out a line of code.

To address this vulnerability, Fernandez et al. introduced "Stable Signature", which integrates the watermarking directly into the Latent Diffusion Model. The process is the following: during image generation, the decoder embeds a key into the output as we've seen in deep watermarking. This key remains hidden within the image.
The model owner then employs an extractor, specifically trained to decode this key from the generated images. If the extractor successfully identifies the key, it confirms that the image was generated by Stable Diffusion.
Incorporating watermarking into the diffusion process minimally affects the image's visual quality.
How can similar techniques be applied to other modalities, like audio?
Audio Watermarking
Now let’s introduce audio watermarking, which can be more challenging because audio often consists of both speech and silence (pauses or no sound). With audio data, watermarking should only be applied to non-silent segments. This prevents attackers from easily isolating and extracting the watermark.
San Roman et al. addressed this issue with AudioSeal, a system that embeds localized audio watermarks that blend seamlessly with the existing audio, making them undetectable by the human ear. This is done by harnessing a deep watermarking setup, where the encoder adds a watermark to the original audio, and the detector has to predict watermarking locally (at different time steps).

Now let's see how we approach watermarking with your favorite large language model.
LLM Watermarking 101
Watermarking for LLMs
A key insight is that LLM output watermarking is primarily applied during the sampling phase, where the model selects tokens based on private information known exclusively to the person running the model.
By favoring less probable tokens using this private heuristic, the repeated application of this strategy leads to output that is statistically unlikely to occur without the specific model and its particular sampling method. This approach allows model owners to verify whether a given output originated from their model.
Greenlist/Redlist Sampling Technique
The main text watermarking method is the "Greenlist/Redlist sampling" (Kirchenbauer et al.), here is the overall process:
The last few generated tokens are hashed using a private hash function, providing a random seed that defines the green/red token split. This way the split is renewed each time a token is generated.
Green list tokens are favored by adding a fixed value to their logits.
Here is an animation breaking down the different steps involved in this text watermarking technique during inference:
Figure 6. How watermark is created during text generation. Credits: Raphael Vienne
At detection time, a score is incremented if a generated token is in the green list. This scoring allows for statistical validation of whether an output was generated by the model. A binomial test distinguishes between watermarked and non-watermarked output based on the expected green/red token distribution.
Here is a short animation representing the detection process:
Figure 7. How a text is classified as AI-generated or not using watermarks. Credits: Raphael Vienne
Watermarking For Ownership
New research suggests that watermarking can be used to detect illegal trainings (training on a models outputs when it's forbidden by the license) and thus be used to ensure ownership.
Radioactive Watermarks
Motivation
Providers of large language models (LLMs) might want to protect their outputs from competitors who could train on them for instruction fine-tuning or reinforcement learning from human feedback (RLHF).
But how can this be practically verified?
Watermarking is an ideal solution because it can help detect unauthorized training without compromising output quality. Sander et al. demonstrated that watermarking makes the outputs of a model radioactive and that the watermarks propagate through any subsequent models trained on the radioactive outputs.
We'll use "Bob" to represent the attacker and "Alice" to denote the defender (LLM provider). The key question is:
"Did Bob train his model using outputs from Alice's model?"
We’ll denote data and model access scenarios according to the following tables:
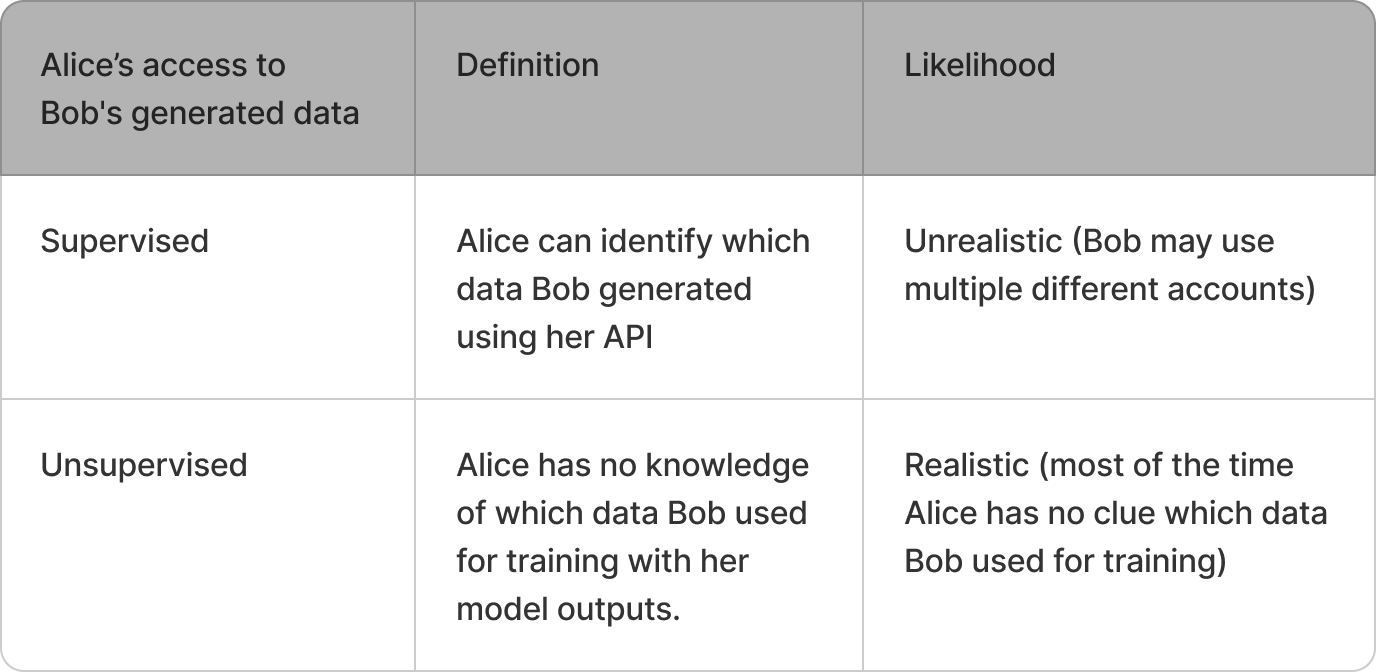

A key insight is that watermarking is effective across all scenarios, while without watermarking, detection is only possible in the Open-Supervised scenario via what we call a membership inference attack (MIA).
We'll use ρ to denote the proportion of Alice’s watermarked data in Bob’s fine-tuning instruction dataset.
Membership Inference Attack (MIA)
In the Open + Supervised scenario, it's possible to detect if Bob trained his model on Alice's data through a Membership Inference Attack. Here’s how Alice can proceed:
Denote the proportion of data that Bob generated from Alice's model and used to train his own model as d.
Compare the probability density distributions of the loss (perplexity) for two groups:
Group 1: Data that Alice suspects Bob trained on.
Group 2: Outputs from Alice’s model that Bob is not suspected to have used.
If Bob has trained extensively on the suspected outputs (with a sufficiently high d), the two distributions should not overlap perfectly, revealing that Bob likely used Alice’s data for training.
Here is an animation breaking down this process:
Figure 8. The Membership Inference Attack. Credits: Raphael Vienne
Watermarking in practice
Watermarking techniques can detect unauthorized training in most scenarios, achieving p-values below 1e-5 (chances that our observation is due to chance) even when a very small portion of the training data (as little as 5%) is watermarked.
Key Insights on Watermarking Radioactivity
Window Size: The smaller the window size k (number of previous tokens used for hashing), the easier it is to detect radioactivity.
Language Differences: It's more challenging to detect radioactivity across different languages due to non-overlapping k-grams, but detection remains possible.
Training Procedure: The training method impacts radioactivity detection. Detection improves under more aggressive training, such as:
Higher learning rates,
More training epochs,
Larger model sizes, and
Absence of adapters like LoRA.
Limitations
Despite being highly effective, watermarking detection has its limitations:
Exclusive Detection: Only Alice (the watermark owner) can identify the unauthorized training. Moreover, it’s not likely that Alice can deploy a detector through an API, because attackers could use the API to gain information on the watermarking process.
Vulnerability to Removal: Watermarks can potentially be removed, such as through denoising attacks in images.
Conclusion
All in all, it seems that watermarking, in particular the deep watermarking process, appears to be the most robust framework for assessing whether content is AI-generated as well as enforcing the responsible use of generative models licenses and terms of use.
Still, we need to keep going forward for more robust techniques, as not all open-weights models currently enforce built-in watermarking.
End note
This article stems from a talk that Tom Sander gave at datacraft. Tom is a PhD student at Meta who is working on privacy preserving methods for deep learning models, as well as watermarking techniques. I would like to thank Tom for his time, his excellent talk as well as his help in reviewing this article. If you're interested in watermarking as well as privacy topics, you should definitely follow Tom's work closely.
Feel free to subscribe to my channel to be notified of my future articles and share this post to anyone that might interested.
Thank you for citing our works. "Image watermarks that meet all three criteria belong to a family of watermarking called “Deep Watermarking”" I would disagree. Deep watermarking simply means watermarking based on deep learning networks, in contrast to traditional `hand-crafted' watermarking schemes from the 2000s (which already obtained good results in imperceptibility, robustness and capacity).